3장. Optimizer 개요
학습 목표
이번 장을 완료하면 다음과 같은 작업을 수행 할 수 있다.
- SQL 문장의 수행 단계를 설명 할 수 있다.
- Optimizer가 필요로 하는 것들을 설명 할 수 있다.
- 최적화 과정의 내부 수행 절차를 설명 할 수 있다.
- Optimizer의 동작을 제어 할 수 있다.
SQL(Structured Query Language)

그림 3.1
SQL은 모든 프로그램들과 사용자들이 Oracle Database 내의 데이터에 액세스 할 때 사용하는 언어이다.
애플리케이션 프로그램들과 Oracle 툴들은 때때로 사용자들이 SQL을 직접 사용하지 않고 Database에
접근 할 수 있도록 해주지만, 이러한 애플리케이션들은 사용자의 요청을 실 행 할 때 사용자 또는
애플리케이션을 대신하여 SQL을 사용한다. 본 시스템은 산업 표준을 준수 하며 SQL 표준위원회(ANSI 및
ISO)에 활동적으로 참여하고 있다. 가장 최근의 SQL 표준은 2003 년 7월에 채택되었으며, 이를
SQL:2003이라고 부른다. SQL 문장은 6개의 주요 집합으로 분류 할 수 있다.
① DML(Data Manipulation Language) 문장은 기존 스키마 객체들의 데이터를 조작하거나 쿼리한다.
② DDL(Data Definition Language) 문장은 스키마 객체를 정의, 구조 변경, 제거한다.
③ TCS(Transaction Control Statements)는 DML 문장에 의해 수정된 변경사항을 관리하고 DML 문장을 트랜잭션으로 그룹화 한다.
④ System Control Statements는 Oracle Database Instance의 속성을 변경한다.
⑤ Session Control Statements는 특정 사용자 세션의 속성을 관리한다.
⑥ 임베디드 SQL 문장은 PL/SQL과 Oracle 프리 컴파일러와 같은 절차적 언어 프로그램 내부에 포함된
DDL, DML, TCS이다. 이러한 포함된 문장은 위 그림의 ESS 범주에 해당된다.
참고 : SELECT 문장은 가장 많이 사용되는 문장이다. 이 과정의 나머지 부분에서는 주로 쿼리에 집중하고
있지만, 모든 형태의 SQL 문장이 최적화 대상이 됨을 인식하는 것이 중요하다.
SQL 문장 표현

그림 3.2
Oracle Database는 실행해야 할 각 SQL 문장들을 공유 SQL 영역(Shared SQL Area) 및 개별 SQL 영역
(Private SQL Area)으로 표현한다. Oracle Database는 두 명의 사용자가 동일한 SQL 문장을 실행한 경우,
해당 사용자들의 공유 SQL 영역을 언제 재사용 해야 될 것인지를 인식한다.
공유 SQL 영역은 해당 문장을 실행하는데 필수적인 모든 최적화 정보를 포함하고 있으며, 한편, 개별
SQL 영역은 해당 문장의 특별한 실행과 관련된 모든 실시간 정보를 포함하고 있다.
Oracle Database는 SQL 문장을 여러 번 반복해서 실행해야 하는 경우, 하나의 공유 SQL 영역을 사용하여
메모리를 절약한다. 많은 사용자들이 동일한 애플리케이션을 사용하는 경우에 이런 상황이 자주 발생한다.
참고 : 문장들이 유사한지 또는 동일한지 판단 할 때, Oracle Database는 사용자 및 애플리케이션에 의해
직접 실행한 SQL 문장 뿐만 아니라, DDL 문장에 의해 내부적으로 실행된 재귀 SQL 문장도 고려한다.
SQL 문장 구현

그림 3.3
Oracle Database는 다양한 목적으로 메모리 구조를 생성하고 사용한다. 예를 들어, 메모리에는 실행된
프로그램 코드와 사용자들에 의해 공유되는 데이터, 각각의 연결된 사용자들에 대한 개별 데이터 영역을
저장한다. Oracle Database는 새로운 SQL 문장이 파싱 될 때, 그 결과를 공유 SQL 영역에 저장하기 위해
Shared Pool에 메모리를 할당 받는다. 이 메모리의 크기는 문장의 복잡성에 따라 달라진다. 만약, 전체
Shared Pool이 이미 모두 할당되어 공간이 부족하다면, Oracle Database는 수정된 LRU(Least Recently
Used) 알고리즘을 이용하여 새로운 문장을 저장할 공유 SQL 영역이 충분한 빈 공간을 확보 할 수 있을
때까지, 메모리 공간 내에 기존 항목들이 할당 받은 공간을 해제한다. 만약, Oracle Database가 이러한
공유 SQL 영역을 해제하면, 이 영역과 관련된 SQL 문장은 반드시 다시 파싱되어야 하고, 다음 번 문장
실행 시, 다른 공유 SQL 영역을 재할당 받아야 한다.
SQL 문장 처리 : 개요

그림 3.4
위 그림은 쿼리 실행 시에 포함된 모든 단계를 보여준다.
SQL 문장 처리 : 단계
1. 커서 생성
2. 문장 파싱
3. 쿼리 결과 표현
4. 쿼리 출력 정의
5. 변수 바인딩
6. 문장 병렬화
7. 문장 실행
8. 쿼리에서 행을 인출
9. 커서 닫기
모든 문장들이 다음과 같은 모든 단계를 요구하는 것은 아니다. 예를 들어, 병렬화되지 않은 DDL 문장은
단지 두 단계(생성과 파싱)를 포함한다. 병렬화 된 문장은 실제 병렬 실행 구조를 구성하는 과정에 해당
문장이 병렬화 가능한지 결정하는 단계가 포함된다.
단계 1 : 커서 생성
커서는 클라이언트 프로그램 내의 커서 데이터 영역과 Oracle 서버의 데이터 구조 간의 연결로 생각 할
수 있다. 대부분의 Oracle 툴들은 해당 사용자로부터 처리된 커서의 많은 부분을 감추고 있지만,
OCI(Oracle Call Interface) 프로그램은 쿼리 실행의 각 부분을 별도로 처리 할 수 있는 유연성을 제공한다.
그러므로, 프리 컴파일러는 명시적 커서 정의를 허용한다. 또한, DBMS_SQL 패키지를 사용해서 이러한
작업의 대부분을 수행 할 수 있다.
핸들은 머그잔의 손잡이와 유사하다. 핸들을 잡고 있으면, 커서를 가지고 있는 것이다. 핸들은 한 번에
하나의 프로세스에 의해서만 얻어 질 수 있는 특별한 커서에 대한 고유 식별자이다.
프로그램들은 SQL 문장을 처리하기 위해 반드시 커서를 오픈해야 한다. 커서는 현재 행에 대한 포인터를
포함하며, 이 포인터는 처리할 행들이 더 이상 남아 있지 않을 때까지 이동하며 행들을 인출한다. 다음
그림은 커서 관리를 설명하기 위해 DBMS_SQL 패키지를 사용하는 것이다. 이 패키지에 친숙하지
않은 사용자들에게는 혼란이 발생 할 수 있지만, PRO*C 또는 OCI보다는 매우 친숙 할 것이다. 여기서는
FETCH와 EXECUTE가 함께 실행된다는 점에 약간의 문제가 있어서, 실행 단계는 트레이스 내에서 별도로
인식되지 않는다.
단계 2 : 문장 파싱
파싱이 진행되는 동안, SQL 문장은 유저 프로세스에서 Oracle Instance로 전달되며, SQL 문장의 파싱된
표현식은 공유 SQL 영역에 로딩 된다.
번역(translation)과 검증(verification) 단계는 해당 문장이 이미 라이브러리 캐시에 존재하는지를 확인한다.
분산된 문장의 경우, Database 링크의 존재 여부를 확인한다.
일반적으로, 파싱 단계는 쿼리 실행 계획이 작성되는 단계로 표현 될 수 있다.
파싱 단계는 네트워크 트래픽을 감소시키기 위해 클라이언트 소프트웨어에 의해 지연 될 수 있다. 이것이
의미하는 것은 PARSE가 EXECUTE에 포함됨을 의미하며, 그 결과 서버간의 라운드 트립은 감소한다.
참고 : 문장이 동일한지 여부를 확인 할 때, 이 문장들이 대소문자 및 공백을 포함하여 반드시 일치되어야 한다.
단계 3 및 4 : 설명과 정의
단계 3 : 설명(Describe)
설명 단계는 쿼리 결과의 특징들이 알려져 있지 않은 경우에만 수행된다. 예를 들어, 쿼리가 인터렉티브
하게 사용자로부터 입력된 경우이다. 이 경우에 설명 단계는 쿼리 결과의 특징들(데이터 타입, 길이, 이름)
을 결정한다. 이 단계는 애플리케이션에게 필요한 SELECT 목록을 알려준다.
예를 들어, 사용자가 다음과 같은 쿼리를 입력하였다.
SQL> select * from employees;
이 경우에 Employees 테이블의 컬럼들에 대한 정보가 필요하다.
단계 4 : 정의
정의 단계에서 사용자는 각각의 인출된 결과를 받기 위해 변수의 위치, 길이, 데이터 타입을 정의 한다.
이러한 변수들을 정의 변수라고 부른다. Oracle Database는 필요한 경우, 데이터 타입 변환을 수행한다.
이러한 두 단계는 SQL*Plus와 같은 툴에서는 사용자에게 감추어져 있다.
그러나, DBMS_SQL 또는 OCI를 사용하면, 클라이언트에게 출력 데이터가 무엇인지, 해당 설정 영역이
어떤 것인지 알려 줄 수 있다.
단계 5 및 6 : Bind 및 병렬화
단계 5 : Bind
이 단계에서 Oracle Database는 SQL 문장의 의미를 파악하지만, 해당 문장을 실행하기 위한 충분한
정보를 갖지는 못한다. Oracle Database는 문장에 나열된 모든 변수들에 대하여 값을 요청한다. 이러한
값을 얻는 과정을 변수 바인딩이라고 부른다.
단계 6 : 병렬화
Oracle Database는 SQL 문장(SELECT, INSERT, UPDATE, MERGE, DELETE)과 인덱스 생성, 서브 쿼리를
이용한 테이블 생성, 파티션에 대한 작업과 같은 일부 DDL 작업의 실행을 병렬화 할 수 있다. 병렬화는
SQL 문장의 작업을 처리하기 위해 여러 개의 서버 프로세스를 사용하며, 빠르게 작업이 완료 될 수 있다.
병렬화는 여러 개의 슬레이브 프로세스들에게 문장의 작업을 분담하는 과정을 포함한다.
파싱은 문장이 병렬화 가능한지 여부를 이미 인식하고 있으며, 적절한 병렬 계획을 구성한다. 실행 시,
이 계획은 충분한 자원이 사용 할 수 있을 때만 구현된다.
단계 7에서 9
이 단계에서 Oracle Database는 모든 필요 정보와 자원을 갖기 때문에 해당 문장을 실행 할 수 있다.
만약, 문장이 쿼리(FOR UPDATE 절이 없는)라면, 어떠한 데이터도 변경되지 않기 때문에 어떠한 행도
잠금을 설정 할 필요가 없다. 만약, 해당 문장이 UPDATE 또는 DELETE 문장이라면, 문장에 의해 영향을
받는 모든 행들은 해당 트랜잭션에 대한 COMMIT, ROLLBACK, SAVEPOINT가 발생할 때까지 잠금이
설정된다. 이것은 데이터의 무결성을 보장해준다.
일부 문장의 경우, 문장의 실행 회수를 지정 할 수 있다. 이것을 배열 처리(array processing)라고 부른다.
실행 횟수 n이 주어지면, 배열 크기인 n부터 Bind 및 정의가 이루어진다.
인출 단계에서 행들은 선택되고 정렬되며(쿼리의 요청이 있다면), 각각의 연속된 인출 작업이 마지막 행이
인출 될 때까지 진행된다. SQL 문장 처리의 최후 단계는 커서를 닫는 것이다.
SQL 문장 처리 PL/SQL : 예제

그림 3.5
이 예제는 앞서 설명한 여러 단계를 요약한 것이다.
참고 : 이 예제에서 인출 작업은 보여지지 않는다. 또한, 한번의 호출로 EXECUTE와 FETCH를 함께
수행하기 위해 EXECUTE_AND_FETCH내에서 EXECUTE 및 FETCH 작업을 결합하는 것도 가능하다. 이
경우는 원격 Database를 사용하는 경우, 네트워크 라운드 트립 회수를 감소시킨다.
SQL 문장 파싱 : 개요

그림 3.6
파싱은 SQL 문장 처리 과정 중 하나의 단계이다. 애플리케이션이 SQL 문장을 실행하면, 애플리케이션은
Oracle Database에게 파싱을 요청한다.
파싱 요청이 진행되는 동안, Oracle 데이터베이스는 다음과 같은 작업을 수행한다.
① 문장에 대하여 구문 및 문법의 유효성을 확인한다.
② 문장을 실행한 프로세스가 해당 문장을 실행 할 수 있는 권한을 가지고 있는지 결정한다.
③ 해당 문장에 대하여 개별 SQL 영역을 할당한다.
④ 라이브러리 캐시 내에 문장의 파싱된 표현이 포함된 공유 SQL 영역이 존재하는지 여부를 결정한다.
만약, 그런 경우, 유저 프로세스가 이러한 파싱된 표현을 사용하고 즉시 해 당 문장을 실행한다. 그렇지
않은 경우, Oracle Database는 해당 문장의 파싱된 표현을 작성하고, 해당 유저 프로세스는 라이브러리
캐시 내에 해당 문장에 대한 공유 SQL 영역을 할당하고, 파싱된 표현을 저장한다. 애플리케이션이 SQL 문장에
대하여 파싱을 요청하는 작업과 Oracle Database가 실제로 문장을 파싱하는 작업 간의 차이점을 구분하여야 한다.
⑤ 애플리케이션에 의한 파싱 요청은 SQL 문장과 개별 SQL 영역을 연결시킨다. 문장이 개별 SQL 영역과
연결되면, 애플리케이션의 파싱 요청 없이도 해당 문장은 반복적으로 실행 가능하다.
⑥ Oracle Database에 의한 파싱 작업은 SQL 문장에 대하여 공유 SQL 영역을 할당하는 것이다.
문장에 대하여 공유 SQL 영역이 할당되면, 재 파싱 없이도 해당 문장을 반복적으로 실행 할 수 있다.
파싱 요청과 파싱은 모두 문장의 실행에 비해 상대적으로 비용이 높을 수 있으므로, 가능하면 가끔 수행되어야 한다.
참고 : 비록 SQL 문장의 파싱이 해당 문장을 검증 할 지라도, 파싱은 문장의 실행 전에 발견 할 수 있는 오류만을 식별한다.
그러므로, 일부 오류는 파싱 단계에 의해서 발견되지 않을 수도 있다. 예를 들어, 데이터 변환 과정에서 오류, 데이터 오류
(기본키에 중복된 값의 입력 시도와 같은), 데드락은 실행 단계에서만 접할 수 있고 보고 될 수 있는 오류들이다.
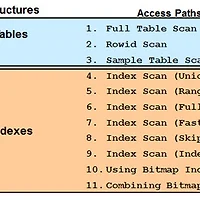
Optimizer가 필요한 이유

그림 3.7
Optimizer는 가능한 빠르게 올바른 결과를 리턴하여야 한다.
쿼리 Optimizer는 SQL 문장에 의해 액세스되는 스키마 객체(테이블 또는 인덱스)에 대한 통계를 기반으로 한 정보를
수집하고 사용 가능한 액세스 경로를 고려하여 어떤 실행 계획이 가장 효율적인지를 결정하기 위해 노력한다.
쿼리 Optimizer는 다음과 같은 단계를 수행한다.
1. Optimizer는 사용 가능한 액세스 경로를 기반으로 SQL 문장에 대한 잠재적 실행 계획 집합을 생성한다.
2. Optimizer는 문장에 의해 액세스 되는 테이블 및 인덱스의 데이터 분포 및 저장 구조의 특성에 대한
데이터 딕셔너리의 통계를 기반으로 각 실행 계획의 비용을 예측한다.
3. Optimizer는 실행 계획의 비용을 비교하고 가장 낮은 비용의 실행 계획을 선택한다.
참고 : 특정 쿼리에 대하여 가장 우수한 실행 계획을 찾는 것은 매우 복잡하기 때문에 옵티마이저의
목표는 비용이 가장 낮은 실행 계획이라고 부르는 우수한(good) 실행 계획을 찾는 것이다.

그림 3.8
그림의 예제는 통계자료가 변경된 경우, Optimizer가 실행 계획을 선택하는 과정을 보여준다.
이 경우에 통계자료는 사원 중에 80%가 매니저임을 보여주고 있다. 이와 같은 가정에서는 전체 테이블
스캔이 인덱스를 사용하는 것보다 나은 해법이 될 수도 있다.
하드 파싱 작업을 수행하는 동안의 최적화
그림 3.9
Optimizer는 SQL 문장에 대한 실행 계획을 생성한다.
시스템에 전달된 SQL 쿼리들은 파서를 통하여 최초 실행되며, 파서는 구문이 올바른지 확인하고 문법을
분석한다. 이 단계의 결과를 해당 문장의 파싱된 표현이라고 부르며, 쿼리 블록들의 집합으로 구성된다.
쿼리 블록은 테이블에 대한 자기 포함(self-contained) DML이다.
쿼리 블록은 최상 위 수준 DML 또는 서브쿼리가 될 수도 있다. 이러한 파싱된 표현은 Optimizer에게
전송되고, 옵티마이저는 세 가지 주요 기능 : 변환, 예측, 실행 계획 작성을 수행한다.
모든 비용 계산을 수행하기 앞서, 시스템은 사용자의 문장을 등가 문장으로 변환하고 등가 문장의 비용을
계산한다. Oracle Database의 버전에 따라 수행 불가능한 변환이 있으며, 일부는 항상 수행되고, 일부는
수행되었다가 비용을 평가하고 버려진다.
쿼리 변환기로의 입력은 파싱된 쿼리이며, 상호 연관된 쿼리 블록의 집합으로 표현된다. 쿼리 변환기의
주요 목적은 쿼리의 구조를 변경하여, 더 나은 쿼리를 생성함으로써 이득이 발생하는지를 결정하는
것이다. 일부 쿼리 변환 기술 예를 들어, 이행(transitivity), 뷰 머지(view merging),
조건 절 주입(predicate pushing), 서브쿼리 중첩 해제(subquery unnesting), 쿼리 재 작성(query rewrite),
스타 변환(start transformation), OR 확장(OR expansion)과 같은 것들이 쿼리 변환기에 포함되어 있다.
변환기 : OR 확장 예제

그림 3.10
만약, 쿼리가 OR 연산자로 결합된 다중 조건의 WHERE 절을 포함하고 있다면, Optimizer는 이 조건절을
UNION ALL 집합 연산자를 사용하는 등가 쿼리로 변환한다. 단, 이러한 변환은 변환 후 쿼리가 변환
전 쿼리보다 더욱 효율적으로 실행되는 경우에만 해당한다.
예를 들어, 각 조건이 개별적으로 사용 가능한 인덱스 액세스 경로를 가지고 있다면, Optimizer는 이러한
변환을 수행 할 수 있다. Optimizer는 해당 테이블을 서로 다른 인덱스를 이용하여 액세스한 다음 그
결과를 모으는 문장으로 변환하고, 해당 실행 계획을 선택한다. 이러한 변환은 예측된 비용이 원본 문장의
비용보다 낮을 때만 수행된다.
위 예제에서는 JOB과 DEPTNO 컬럼에 모두 인덱스가 정의되어 있다고 가정하였다. CBO가 쿼리 변환을
결정하였다면, Optimizer는 원본 쿼리가 전체 테이블 스캔을 수행 했을 때의 비용과 비교한다.
변환 : 서브쿼리 중첩 전개(Subquery Unnesting) 예제

그림 3.11
중첩 된 쿼리를 전개하기 위해 Optimizer는 원본 쿼리를 등가 JOIN 문장으로 변환하고 JOIN 문장을
최적화 할 수도 있다. Optimizer는 JOIN 문장의 실행 결과가 원본 문장의 실행 결과와 정확히
일치한다는 것을 보장 할 수 있을 때만 이러한 변환을 수행 할 수 있다. 이 변환은 Optimizer가 조인
최적화 기술의 장점을 얻을 수 있도록 해준다.
위 예제에서, customers 테이블의 CUSTNO 컬럼이 기본 키 또는 UNIQUE 제약조건을 가지고 있다면
Optimizer는 복잡한 쿼리를 JOIN 문장으로 변환하여 동일한 데이터가 리턴됨을 보장해준다.
만약, 복잡한 문장이 JOIN 문장으로 변환 될 수 없다면, Optimizer는 메인 쿼리와 서브쿼리를 별도의
문장으로 실행하는 실행 계획을 선택한다. 그런 다음, Optimizer는 서브쿼리를 실행하고 리턴된 결과를
메인 쿼리에 전달하여 실행한다.
참고 : 복잡한 쿼리란 서브쿼리가 AVG와 같은 집계 함수를 포함하고 있어서 JOIN 문장으로 변환 될 수
없는 서브쿼리를 의미한다.
변환 : 뷰 머지(View Merging) 예제

그림 3.12
뷰의 쿼리를 뷰를 액세스하는 문장 내의 쿼리 블록 내부로 머지하려면, Optimizer는 뷰의 이름을 쿼리
블록 내부의 기본 테이블의 이름으로 교체하고 뷰에 정의된 문장의 WHERE절 조건을 뷰를 액세스하는
쿼리 블록의 WHERE 절에 추가한다.
이 최적화는 select-project-join 뷰에만 적용 할 수 있는데, 이 뷰는 오직 select, project, join 연산 만을
포함하고 있어야 한다. 즉, 뷰는 집합 연산자, 집계 함수, DISTINCT, GROUP BY, CONNECT BY 등을 포함하면 안 된다.
이 예제에서 뷰는 10번 부서에서 근무하는 모든 사원을 검색한다.
쿼리는 뷰에 액세스하고, 해당 쿼리는 10번 부서에 근무하는 사원들 중에 ID가 780을 초과하는 사원을 검색한다.
Optimizer는 쿼리를 뷰의 기본 테이블에 접근하는 등가 변환 쿼리로 변환 할 수 있다.
만약, DEPTNO 또는 EMPNO 컬럼에 인덱스가 존재한다면, 변환된 문장의 WHERE 구문은 이러한 인덱스를 사용 할 수 있다.
변환 : 조건절 주입 예제

그림 3.13
Optimizer는 머지가 불가능한 뷰에 액세스하는 쿼리 블록의 경우, 쿼리 블록의 조건절을 뷰의 쿼리
내부로 주입한다. 예제에서 two_emp_tables 뷰는 두 개의 employee 테이블의 합집합이다. 이 뷰는
UNION 집합 연산자를 사용하는 복합 쿼리로 정의되어 있다.
그림에서 쿼리는 뷰를 액세스하며, 두 테이블에서 20번 부서에 근무하는 사원들의 ID와 이름을 검색한다.
뷰는 복합 쿼리로 정의되어 있기 때문에 Optimizer는 뷰의 쿼리를 뷰를 액세스하는 쿼리 블록으로 머지
할 수 없다. 대신, Optimizer는 뷰를 액세스하는 문장의 조건절을 뷰 내부로 주입하여 문장을 변환한다.
여기서는 WHERE 절의 조건 deptno=20이 뷰의 복합 쿼리 내부로 주입되었다. 그 결과, 등가 변환 쿼리는 그림과 같다.
만약, 두 테이블의 DEPTNO 컬럼에 인덱스가 정의되어 있다면, WHERE 절은 해당 인덱스를 사용 할 수 있다.
변환기 : 이행 예제

그림 3.14
만약, WHERE 절의 두 조건이 공통 컬럼을 포함하고 있다면, Optimizer는 이행 원리를 사용하여 세 번째
조건을 추론 할 수 있다. 그런 다음, Optimizer는 추론된 조건을 사용하여 해당 문장을 최적화한다.
추론된 조건은 원본 조건에서는 사용 할 수 없었던 인덱스 액세스 경로를 사용 할 수 있게 된다.
위 예제에서 원본 쿼리의 WHERE 구문은 두 개의 조건을 포함하고 있으며, 각각 EMP.DEPTNO 컬럼을
사용한다. 이행을 사용하여 Optimizer는 DEPT.DEPTNO=20 조건을 추론한다.
만약, DEPT.DEPTNO 컬럼에 인덱스가 존재한다면 이 조건은 해당 인덱스를 사용하는 액세스 경로를 선택 할 수 있다.
참고 : Optimizer는 컬럼이 다른 컬럼과 연관된 경우가 아닌, 컬럼이 상수 표현식과 연관된 경우에 대해서만 조건을 추론한다.
비용 기반 Optimizer
예측기와 실행 계획 작성기의 조합을 보통 비용 기반 Optimizer(CBO)라고 부른다.
예측기는 3가지 형식의 측정 단위 : 선택도, 카디널리티, 비용을 생성한다. 이러한 측정값은 서로 연관되어 있다.
카디널리티는 선택도로부터 파생되며, 비용은 카디널리티에 의존적이다. 예측기의 최종 목표는 주어진
실행 계획의 전체 비용을 예측하는 것이다. 만약, 통계자료가 사용 가능하다면 예측기는 이를 이용하여
측정값 계산의 정밀도를 향상시킨다.
실행 계획 작성기의 주요 기능은 주어진 쿼리에 대하여 서로 다른 실행 계획을 테스트하고 가장 낮은
비용을 갖는 하나의 실행 계획을 선택하는 것이다. 여기에는 서로 다른 많은 실행 계획이 가능하다. 그
이유는 동일한 결과를 만들 수 있는 방법에는 다양한 액세스 경로, 조인 방법, 조인 순서들을 조합 할
수 있기 때문이다. 쿼리 블록에 대하여 사용 가능한 실행 계획의 개수는 FROM 절의 조인 항목의 개수에
비례하여 증가한다. 이 숫자는 조인 할 항목의 수에 따라 기하급수적으로 증가한다.
Optimizer는 WHERE절, 통계자료, 초기화 파라메터, 제공된 힌트, 스키마 정보 등의 다양한 정보를
이용하여 최상의 경로를 결정한다.
예측기 : 선택도
선택도는 전체 행 집합의 일부를 표현한다. 행 집합은 기본 테이블, 뷰, 조인 결과, GROUP BY 연산자의
결과가 될 수도 있다. 선택도는 last_name=’Smith’ 또는 last_name=’Smith’ AND job_type=’Clerk’와
같은 조건절의 결합과 밀접하게 연관된다. 조건절은 행 집합에서 특정 행들을 선택하는 필터로 동작한다.
그러므로, 조건절의 선택도는 전체 행 집합에서 조건절을 통과한 행들 의 비율을 나타낸다.
선택도는 0.0에서 1.0의 범위를 갖는다. 선택도가 0.0이라는 것은 전체 행 집 합에서 어떠한 행도
선택되지 않음을 의미하며 1.0은 모든 행들이 선택되었음을 나타낸다.
만약, 사용 가능한 통계 자료가 존재하지 않으면, OPTIMIZER_DYNAMIC_SAMPLING 초기화 파라메터의
값에 따라 Optimizer는 동적 샘플링을 사용하거나 내부 디폴트 값을 이용한다. 통계 자료를 사용 할 수
있으면, 예측기는 선택도를 예측하는데 있어서 이 자료를 이용한다. 예를 들어, 등가 조건
(last_name=’Smith’)의 경우, 선택도는 LAST_NAME 컬럼의 고유한 값의 개수인 n의 역수이다.
그 이유는 쿼리가 n개의 고유 값 중 하나를 포함하는 행들을 선택하기 때문이다. 만약, LAST_NAME
컬럼에 사용가능한 히스토그램이 존재하면, 예측기는 고유 값의 개수 대신에 히스토그램을 사용한다.
히스토그램은 컬럼에 저장된 값들의 분포를 캡처하여 더 나은 선택도를 예측 할 수 있도록 해준다.
참고 : 값이 중복되고 분포가 일정하지 않은 컬럼에는 히스토그램을 정의하는 것이 중요하다.
예측기 : 카디널리티
카디널리티 선택도 전체 행의 갯수
쿼리의 실행 계획에서 특정 작업의 카디널리티는 해당 특정 작업에 의해 리턴된 행의 개수를 예측한
것이다. 대부분의 경우, 행 집합의 원본은 기본 테이블, 뷰, 조인 결과, GROUP BY 연산자의 결과이다.
조인 작업이 비용을 예측하는 경우, 드라이빙 행 집합의 카디널리티를 알아내는 것이 중요하다. 중첩 루프
조인의 경우, 드라이빙 행 집합이 내부 행 집합을 얼마나 자주 검색하여야 하는지 결정한다.
정렬 비용은 정렬해야 할 행들의 규모와 개수에 따라 달라지므로 카디널리티는 정렬 비용을 계산 하는데
아주 중요하다.
SELECT day FROM courses WHERE dev_name = ‘ANGEL’;
① DEV_NAME의 고유한 값의 개수는 203개
② COURSE 내의 행의 개수는 1018건
③ 선택도 = 1 / 203 = 4.926*e-03
④ 카디널리티 = (1/203) * 1018 = 5.01 (6으로 올림)
위 예제는 통계 자료를 기반으로 Optimizer가 DEV_NAME 컬럼에 203개의 고유 값이 존재하는 것과
COURSES 테이블에 1018건의 행이 저장되어 있음을 알고 있다. 이러한 사실을 기반으로 옵티마이저는
DEV_NAME=’ANGEL’ 조건의 선택도가 1/20이라는 것(히스토그램은 존재하지 않는다고 가정)과 해당
쿼리의 카디널리티가 (1/203)*1018이라는 것을 추론한다. 이 값은 소수점을 올림 하여 6이 된다.
예측기 : 비용

그림 3.15
문장의 비용은 해당 문장을 실행하는데 소요된 표준 입출력(I/O)의 횟수를 Optimizer가 예측한 것이다.
기본적으로 비용은 단일 블록 랜덤 읽기 횟수로 정규화 된 값이다.
Optimizer에 의해 예측된 표준 비용은 단일 블록 랜덤 읽기 횟수로 표현되므로, 비용이 1이라는 것은
1회의 단일 블록 랜덤 읽기에 해당한다. 위의 공식은 서로 다른 비용 단위를 조합한다.
① 모든 단일 블록 랜덤 읽기를 수행하는데 예측된 시간
② 모든 다중 블록 읽기를 수행하는데 예측된 시간
③ 해당 문장을 처리하는데 CPU에 의해 소모된 예측 시간으로 표준 비용 단위로 환산
이 모델은 대부분의 경우 CPU 이용률이 I/O만큼 중요하기 때문에 CPU 비용을 포함한다.
인 메모리 정렬, 해시, 조건절 평가, 캐시된 I/O와 같은 경우에 CPU 이용률이 비용의 대부분을 차지하기 도 한다.
이 모델은 순차적(serial) 실행에만 적용되며, 병렬 실행의 경우, #SRds, #MRds, #CPUCycles의 예측치를
계산 할 때, 약간의 조정이 필수적이다.
참고 : #CPUCycles에는 쿼리 처리를 위한 CPU 비용(순수한 CPU 비용)과 데이터 리턴(buffer cache get의
CPU 비용)을 위한 CPU 비용이 포함된다.
실행 계획 작성기

그림 3.16
실행 계획 작성기는 서로 다른 액세스 경로, 조인 방법, 조인 순서를 테스트하여 쿼리 블록에 대한 다양한
실행 계획을 탐색한다. 결국, 실행 계획 작성기는 해당 문장에 대한 가장 우수한 실행 계획을 선택한다.
위 그림은 SELECT 문장에 대하여 작성된 Optimizer 트레이스 파일을 추출한 것이다. 트레이스 파일에서
볼 수 있는 것처럼 실행 계획 작성기는 6개의 후보 또는 테스트 할 6개의 실행 계획 : 2가지의 조인 순서,
그리고 각 순서에 대한 3가지의 서로 다른 조인 방법을 보여준다. 예제에서는 인덱스가 존재하지 않는다고 가정한다.
행들을 읽어 오려면, DEPARTMENTS 테이블을 EMPLOYEES 테이블과 조인하여야 한다. Optimizer는
특정한 조인 순서에 대하여 3가지의 조인 메커니즘인 Nested Loop, Sort Merge, Hash Join이 존재함을
알고 있으며, 각각의 경우에 대하여 비용을 가지고 있다. 가장 우수한 실행 계획은 트레이스 파일의
하단에서 볼 수 있다.
실행 계획 작성기는 가장 낮은 비용의 실행 계획을 탐색 할 때, 검토 할 실행 계획의 수를 감소시키기
위해 내부 컷 오프를 진행한다. 컷 오프는 현재의 가장 우수한 실행 계획의 비용을 기반으로 한다. 만약,
현재의 가장 우수한 실행 계획의 비용이 높다면, 실행 계획 작성기는 더 낮은 비 용의 우수한 실행
계획을 검색하기 위해 더 많은 후보 실행 계획을 탐색해야 한다. 만약, 현재의 비용이 매우 낮다면, 더
낮은 비용은 중요하지 않다고 판단하기 때문에 후보 실행 계획의 탐색을 신속히 종료한다. 실행 계획
작성기가 최적 비용에 근접한 비용을 갖는 실행 계획을 생성하는 초기 조인 순서를 가지고 시작한다면
컷 오프 작업은 제대로 동작하게 된다. 그러나, 우수한 초기 조인 순서를 얻는 것은 매우 어려운 문제이다.
Optimizer의 동작 제어
다음 파라메터는 Optimizer의 동작을 제어한다.
① CURSOR_SHARING은 어떤 종류의 SQL 문장이 동일한 커서를 공유 할 수 있는지를 결정 한다.
1. FORCE : 리터럴이 문장의 의미에 영향을 주지 않으며, 일부 리터럴을 제외하고 문장이 동일해야만 커서가 공유된다.
2. SIMILAR : 리터럴이 문장의 의미에 영향을 주지 않거나, 실행 계획의 최적화 수준에 영향을 주지 않으며,
일부 리터럴을 제외하고 문장이 동일해야만 커서가 공유된다. SIMILAR 문장들 간에 커서를 FORCE로
공유하면 DSS 애플리케이션 또는 스토어드 아웃라인을 사용하는 애플리케이션에서 기대하지 못한 결과를
가져올 수도 있다.
3. EXACT : 동일한 커서를 공유하려면 문장이 동일해야 한다. 이 값이 디폴트이다.
② DB_FILE_MULTIBLOCK_READ_COUNT는 전체 테이블 스캔(full table scan) 또는 인덱스 고속 전체 스캔(index fast full scan)이
실행 중인 동안 I/O를 최소화 할 수 있는 파라메터 중의 하나이다. 이 파라메터는 순차적 스캔을 실행하는 동안 1회의 I/O에 의해서
읽어야 할 블록의 최대 개수를 지정한다. 전체 테이블 스캔 또는 인덱스 고속 전체 스캔을 수행 하는데 필요로 하는 I/O의 전체 횟수는
세그먼트의 크기, 파라메터 값, 해당 작업을 병렬 실행으로 수행 할 수 있는지의 여부와 같은 인자에 따라 달라진다.
Oracle Database 10g Release 2에서는 이 파라메터의 디폴트 값이 효율적으로 수행가능한 최대 I/O 크기와 일치한다. 이 값은
플랫폼에 의존적이며 대부분의 플랫폼에서 1MB이다.
해당 파라메터는 블록 수로 표현되기 때문에 효율적으로 실행 가능한 최대 I/O 크기를 표준 블록 크기로 나눈 값으로 자동 계산된다.
만약, 세션의 개수가 매우 많다면, 이 파라메터 값을 감소시켜 버퍼 캐시가 테이블 스캔에 의한 버퍼들로 채워지지 않도록 하여야 한다.
디폴트 값이 매우 크지만, 이 파라메터를 설정하지 않더라도, Optimizer는 큰 값을 선호하지 않는다. 이 파라메터를 명시적으로 큰 값으로
설정하는 경우에만 Optimizer가 이 값을 사용한다. 만약, 이 값을 명시적으로 지정하지 않거나 0으로 지정하면, Optimizer는 디폴트 값으로
8을 사용하여 전체 테이블 스캔과 인덱스 고속 전체 스캔의 비용을 계산한다. OLTP와 배치 환경에서는 이 파라메터를 4~16으로 설정하고,
DSS와 데 이터웨어 하우스 환경에서는 이 파라메터에 지정 가능한 최대 값을 설정하도록 한다. 이 값이 높을수록 Optimizer는 인덱스보다
전체 테이블 스캔을 선택 할 가능성이 높아지게 된다.
③ PGA_AGGREGATE_TARGET는 Instance에 연결된 모든 서버 프로세스에서 사용가능한 전체 PGA 메모리의 합계를 지정한다.
PGA_AGGREGATE_TARGET을 0이 아닌 값으로 지정하는 것은 WORKAREA_SIZE_POLICY 파라메터를 자동으로 AUTO로 지정하는 효과를 갖는다.
이로 인하여 메모리를 과도하게 사용하는 SQL 연산자(정렬, group-by, 해시 조인, 비트맵 머지, 비트맵 생성과 같은)에 의해 사용되는
SQL 작업 영역이 자동적으로 조정됨을 의미 한다. 이 파라메터의 디폴트 값은 별도로 설정하지 않으면, SGA의 20% 또는 10MB 중의
큰 값으로 설정한다. PGA_AGGREGATE_TARGET을 0으로 설정하면 WORKAREA_SIZE_POLICY 파라메터를 MANUAL로 설정하는 것과 같다.
그 결과, SQL 작업 영역의 크기는 *_AREA_SIZE 파라메터를 사용하여 설정된다. 시스템은 작업 영역의 크기를 개별 메모리에 맞춤으로서 이
파라메터에 의해 지정된 값 이하로 개별 메모리의 크기를 유지하려고 시도한다. 이 파라메터의 값을 증가시키면, 작업 영역에 할당 할 메모리를
간접적으로 증가시킨다. 결과적으로, 많은 메모리 위주의 작업들이 메모리 내에서 수 행 될 수 있고, 그 중의 일부는 디스크를 경유하여 수행된다.
이 파라메터를 설정 할 때 는 Oracle Instance가 사용가능한 시스템의 전체 메모리에서 SGA를 뺀 값을 지정한다.
④ STAR_TRANSFORMATION_ENABLED는 비용 기반 쿼리 변환을 스타 쿼리에 적용 할 것인 지를 결정한다.
⑤ 쿼리 최적화기는 초기화 파라메터 파일에서 RESULT_CACHE_MOD의 설정에 따라 결과 캐시(result cache) 메커니즘을 관리한다. 이 파라메터를
사용하여 Optimizer가 자동으로 쿼리의 결과를 결과 캐시에 전송 할 것인지를 결정 할 수 있다. 이 파라메터에 지정 가 능한 값은 MANUAL과 FORCE이다.
1. MANUAL(디폴트)을 설정하거나 RESULT_CACHE 힌트를 지정하여, 특정 결과를 캐시에 저장 할 수 있다.
2. FORCE를 지정하면 모든 결과가 캐시에 저장된다. 문장에서 [NO_]RESULT_CACHE 힌트를 포함하면, 힌트가 파라메터 설정에 우선한다.
⑥ 결과 캐시에 할당될 메모리 크기는 SGA의 메모리 크기와 메모리 관리 시스템에 따라 달라진다. RESULT_CACHE_MAX_SIZE 파라메터의 설정에
따라 결과 캐시에 할당 될 메모리를 변경 할 수 있다. 이 파라메터를 0으로 지정하면 결과 캐시는 비활성화 된다. 이 파라메터 값은 지정 값을 넘지 않는
범위에서 32KB의 정수배가 된다. 이 값이 0이 되면 이 기 능은 비활성화 된다.
⑦ 하나의 단일 결과에 의해 사용될 수 있는 최대 캐시 메모리 크기를 설정하려면 RESULT_CACHE_MAX_RESULT 파라메터를 사용한다. 디폴트 값은
5%이지만 1에서 100 사이에서 자유롭게 설정 할 수 있다.
⑧ 결과가 유지되는 시간(분)을 지정하려면 RESULT_CACHE_REMOTE_EXPIRATION 파라메터 를 사용하며, 원격 Database 객체가 유효한 상태로
유지되어야만 설정이 유효하다. 디폴트 값은 0이며, 원격 객체를 이용한 결과는 캐시되지 않는다. 예를 들어, 이 파라메터를 0이 아닌 값으로 설정하면,
원격 Database에서 결과에 의해 사용된 테이블이 수정되면 올바르지 못한 결과를 얻을 수도 있다.
⑨ OPTIMIZER_INDEX_CACHING : 이 파라메터는 중첩 루프 조인에서 인덱스를 이용한 내부 테이블 검증 또는 inlistiterator의 비용을 제어한다.
OPTIMIZER_INDEX_CACHING 파라메터에 설정 가능한 값은 0에서 100이며, 버퍼 캐시 내에서 인덱스 블록이 발견될 확률을 의미한다. 즉,
중첩 루프와 inlistiterator의 인덱스 캐시에 대한 Optimizer의 가정에 영 향을 준다. 이 값이 100이면 버퍼 캐시 내에서 전체 인덱스 블록이
발견된다고 추론하며, 이에 따라 인덱스 검증 또는 중첩 루프 비용을 조정하게 된다. 이 파라메터를 디폴트 값인 0으로 설정하면, Optimizer는
디폴트로 동작하게 된다. 이 파라메터를 사용 할 때는 매우 주의해야 한다. 그 이유는 실행 계획이 인덱스를 선호하는 방향으로 변경되기 때문이다.
⑩ OPTIMIZER_INDEX_COST_ADJ는 Optimizer가 액세스 경로를 선택하는 과정에서 인덱스의 선호 여부를 설정한다. 즉, Optimizer가 전체 테이블 스캔보다
인덱스 경로를 선택하거나 선택하지 않도록 설정한다. 지정 가능한 값의 범위는 1에서 10000이며, 디폴트 값 은 100 퍼센트이며, 이 때, Optimizer는 인덱스
액세스 경로를 일반 비용과 동일하게 평가한다. 다른 값을 설정하면 Optimizer는 일반 비용에 해당 비율을 곱하여 평가한다. 예를 들어, 이 값을 50으로
설정하면 인덱스 경로는 일반 비용의 반으로 평가된다.
⑪ OPTIMIZER_FEATURES_ENABLED는 Oracle 릴리즈 번호에 기반하여 일련의 Optimizer의 기능을 활성화하는데 사용되는 파라메터로 동작한다. 예를 들어,
Database를 10.1에서 11.1로 업그레이드 하였지만, Optimizer의 기능은 10.1 버전으로 유지하고 싶다면 이 파라메터를 10.1.0으로 설정하면 된다. 최종적으로는
이 파라메터를 11.1.0.6으로 설정하여 향상된 기능을 사용하도록 시도하여야 한다. 그러나, OPTIMIZER_FEATURES_ENABLED 파라메터를 명시적으로 하위 버전으로
설정하는 것은 추천하지 않는다. 실행 계획의 변화로 인한 SQL의 성능 저하를 방지하려면, 이 파라메터 대신에 SQL 실행 계획 관리를 사용하도록 한다.
⑫ OPTIMIZER_MODE는 Instance 또는 세션에서 Optimizer의 디폴트 동작 특성을 설정한다. 설정 가능한 값은 다음과 같다.
1. ALL_ROWS : Optimizer는 통계자료의 존재 여부와 상관 없이 세션 내의 모든 SQL 문장들에 대하여
비용 기반 Optimizer로 동작하고, 가장 우수한 처리량(전체 문장을 완료하는데 사용되는 자원이 최소화)을
갖도록 문장을 최적화한다. 디폴트 값이다.
2. FIRST_ROWS_n : Optimizer는 통계자료의 존재 여부와 상관 없이 비용 기반 옵티마이저로 동작하고,
전체 행 중에서 최초 n개의 행이 가장 빨리 리턴되도록 문장을 최적화한다. n에는 1, 10, 100, 1000을 지정 할 수 있다.
3. FIRST_ROWS : Optimizer는 첫 번째 행이 가장 빨리 리턴되는 실행 계획을 찾기 위해 비용과 경험을 혼합하여 사용한다.
때때로 경험적인 기법은 쿼리 최적화기가 매우 높은 비용을 갖는 실행 계획을 유도하는 경우도 있다. FIRST_ROWS는 역호환성 및
실행 계획 안정성 때문에 아직까지 제공되며, FIRST_ROWS_n을 대신 사용하도록 한다.
⑬ OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES는 반복되는 SQL 문장의 자동 인식 기능을 활성 또는 비활성화며, 해당 문장에
대하여 SQL 실행 계획의 기준선을 생성하기도 한다.
⑭ OPTIMIZER_USE_SQL_PLAN_BASELINES는 SQL Management Base에 저장된 SQL 실행 계 획 기준선의 사용 여부를 활성 및 비활성화 한다.
활성화되면, Optimizer는 컴파일 중인 SQL 문장에 대한 SQL 실행 계획 기준선을 검색한다. 만약, SQL Management Base에서 해당 기준선이
검색되면, Optimizer는 각각의 기준선 실행 계획의 비용을 확인하고 가장 낮은 비용의 실행 계획을 선택한다.
⑮ OPTIMIZER_DYNAMIC_SAMPLING은 Optimizer에 의해 수행되는 동적 샘플링 수준을 제어한다.
만약, OPTIMIZER_FEATURES_ENABLE을 다음과 같이 지정하면,
1. 10.0.0 또는 이후 버전을 지정하면, 디폴트 값은 2
2. 9.2.0 이면 디폴트 값은 1
3. 9.0.1 또는 이전 버전을 지정하면, 디폴트 값은 0
16 OPTIMIZER_USE_INVISIBLE_INDEXES는 보이지 않는(invisible)의 인덱스의 사용 여부를 활성 또는 비활성화한다.
17 OPTIMIZER_USE_PENDING_STATISTICS는 SQL 문장을 컴파일 할 때, Optimizer가 지연(pending) 통계를 사용 할 것인지 여부를 지정한다.
Optimizer 기능과 Oracle Database 버전

그림 3.17
OPTIMIZER_FEATURES_ENABLED는 Oracle 릴리즈 번호에 기반하며 일련의 Optimizer 기능을 활성화시키는 파라메터로 동작한다.
위 표는 OPTIMIZER_FEATURES_ENABLED 파라메터에 지정한 값에 따라 활성화 되는 Optimizer 기능 일부를 설명한 것이다.
'oracle11R2 > SQL Tuning 11g' 카테고리의 다른 글
| 06장. 케이스 스터디 : 스타 변환 (0) | 2011.06.23 |
|---|---|
| 05장. 실행 계획의 해석 (0) | 2011.06.23 |
| 04장. 옵티마이저 연산자 (0) | 2011.06.15 |
| 02장. SQL 튜닝 개요 (0) | 2011.06.15 |
| 01장. 오라클 데이터베이스 아키텍처 (0) | 2011.06.13 |